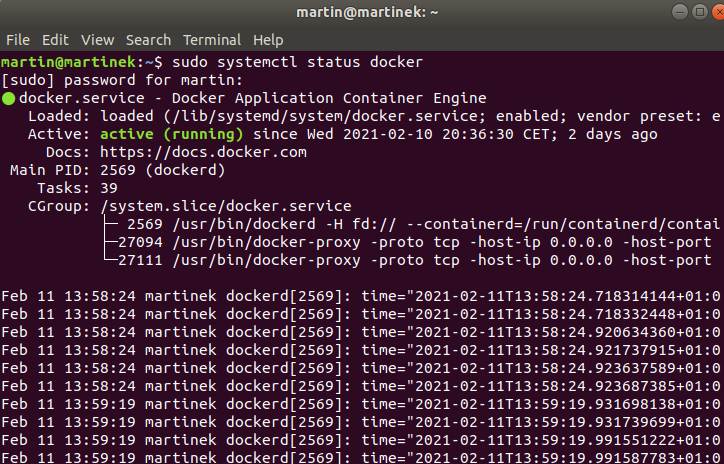
Docker auf einem frischen Ubunto 18.04 installieren geht in wenigen Schritten. Mit frischem meine ich ein System wo noch keine ältere Dockerversion vorher lief.
sudo apt update
Wir holen jetzt paar Pakete die wir für die Docker Installation brauchen rein.
wir ihnen der Docker Status auf ihrem System angezeigt.
Es geht auch noch einfacher. Und zwar mit dem offiziellem “Convenience Script” von Docker. Das ist ein Script welches letzendlich alle commands von oben enthält und nacheinander ausführt. Also für die schnellen unter uns wäre das ganz gut:
Es kommt vor, dass man ein Feature für ein Projekt entwickeln soll und man zuerst ausprobiert was so geht. Ihr arbeitet an einem Remote Repository und entwickelt lokal. Dann schnell mal ein composer update und die composer.lock ist geändert. Ihr wollt am liebsten den ganzen Branch verwerfen und zum Step zurück wo ihr angefangen habt. Ohne Git wäre das jetzt STRESS-PANIK Deluxe. Mit Git super entspannt.
Es gibt natürlich wieder mal mehrere Lösungswege. Ich stelle hier zwei vor:
Der einfachste und schnellste Weg
In seid in dem Branch wo Ihr die Änderungen gemacht habt und ihr aber nicht haben wollt. Dann folgenden Git Command abfeuern:
git reset --hard HEAD
2. Der Lange Weg – aber derhaut auch den ganzen Branche in die Tone
Ein andere Weg wäre nun den gesamten neuen Branch zu entfernen. Wenn ihr euch noch nicht im neuem Branch bewegt könnt ihr mit git checkout neuer_branch in den branch rein. Dann mit git add. && git commit-“Änderungen sind ins leere gelaufen, daher wird dieser branch gelöscht“.
Mit:
git branch -D neuer_branch
löscht ihr den Branch.
Fazit:
Beide Wege sind legitim. Ich nutze aber meistens den ersten Weg (git reset –hard HEAD) weil ich zu 99% den Branch weiter nutzen will.
Wenn irgendwann mal das Internet für längere Zeit ausfallen sollte – Stichwort Cloudausfall – wäre ich gewappnet. Ich habe das Internet bei Firefox in meinen Tabs offen. Vielleicht gehört ihr auch zu denen, die über 1000 Tabs offen haben. Warum auch immer. Wahrscheinlich könnte man darüber eine Doktorarbeit schreiben. Mit dem Titel: „Persönlichkeitsanalyse anhand des Tabverhaltens.“ Bei mir ist es jedenfalls so, dass ich wenn ich etwas Interessantes gefunden habe aber in jenem Moment zu faul bin es bis zum Ende durchzulesen, lasse ich es im Tab offen. Und mit der Zeit kumuliert sich das auf mehrere Hundert offene Tabs. Vielleicht ist bei mir eine versteckte Bindungsphobie inkludiert. Wer weiß das schon.
Irgendwann nimmt die Anzahl der Tabs überhand und die Performance des Rechners lässt nach. Spätestens dann fragt man sich, wie man seine offenen Tabs jetzt backupen kann um sie eventuell in 10 Jahren mal durchzulesen. Also quasi nie. Aber für das gute Gefühl muss das ja gemacht werden.
Es gibt mehrere Möglichkeiten. Man installiert sich eine Firefox Erweiterung. Kann man machen. Hier würde ich den „Session Manager“ an Eurer Stelle mal ausprobieren. Aber es gibt eine viel elegantere Lösung. Und zwar über die Kommandozeile.
Geht zu einem Ordner wo ihr Euer Firefox Session Backup speichern wollt. Falls ihr über den Filemanager den Ordner angelegt habt, dann klickt rein und öffnet über das Mauskontextmenü das Terminal. Ihr sollte Euch jetzt im angelegtem Backup Ordner befinden. Gebt nun folgenden Command ein:
tar -jcvf firefox-browser-session-profile-backup.tar ~/.mozilla
Damit packt ihr den gesamten relevanten Firefox Ordner in eine TAR Datei.
Ca. 10 Jahre später habt ihr ein wenig Zeit gefunden und wollt mal eure alten Tabs durchstöbern. Dann einfach in dem Ordner mit der gepackten Datei rein und das Terminal aufrufen. Dann eingeben:
tar -xvf firefox-browser-profile.tar
Und ihr habt das Internet vor 10 Jahren im Fenster.
Alternativ könnt ihr auch Deja Dup nutzen. Das ist ein Tool mit Userinterface, falls euch das mit der Konsole nicht vertraut erscheint.
Ein wichtiger Baustein der Softwareentwicklung ist die Softwarearchitektur. Ab einer bestimmten Größe steht und fällt, meines Erachtens, ein Projekt mit der Softwarearchitektur. Damit ist nicht gemeint, das prozedural geschriebener Code perse schlecht ist. Im Gegenteil. In der Vergangenheit habe ich mit prozedural geschriebenen Code gute Software gebaut die teilweise bis heute läuft. Ich erinnere mich auch zu gerne an meine Zeit bei der Fincaorca GmbH in Berlin und deren CTO Jens. Dieser hat mit einem weiterem Kollegen 2006 ein Reisebuchungsportal aufgesetzt. Ein sehr großer Teil war dort prozedural geschriebener Code. Wo ich 2016 hinzugestoßen bin, war es ein Mix aus objektorientierten geschrieben Modulen und dem alten prozedural geschriebenen Grundgerüst. Und erst vor kurzem (01/2021!) habe ich erfahren, dass es nun mit einem schönen PHP Framework ersetzt werden soll. Lange Rede, kurzer Sinn. Soll nur heißen, dass eine Software Straight Forward und gut durchdacht sein soll. Pragmatische Ansätze bei wichtigen Entscheidungen, machen das Leben als Softwareentwickler aber auch der Auftraggebers um einiges leichter.
Bei Laravel gibt es von Hause aus nicht das Service Repository Pattern. Jetzt werden einige sagen: Momentmal Controller Model ist doch ein wenig wie Service Repository. Ich sage nein. In den meisten Fällen ist ein Request nicht nur „get-all-users“ (gebe mir alle User) zurück. Sobald eine Komplexität die Abfrage einfärbt ist es Zeit, über ein Service Repository Pattern (SRP) nachzudenken. Aus folgenden Gründen: Spätere Wartung, Änderungen oder Erweiterungen werden definitiv mit diesem Pattern leichter gehen und das bei Gleichzeitiger Fehlerreduktion. Was unterm Strich bedeutet: weniger Stress, mehr Zeit für andere Sachen und Kosten gespart.
Wie geht man also vor?
Stellen wir uns vor: – wir haben ein eShop – der Nutzer befindet sich in seinem Backend und will den Preis seiner letzten Rechnung einsehen – über die Order id wird dieser Prozess angetriggert – wir gehen von einem XHR Request aus – die Order soll sich selbst aber auch ihre Order Items und Summe des Einkaufs netto und UST mitliefern. Damit wir eine schöne Auflistung unserer Produkte haben.
Der Order Controller bekommt den Request mit einer OrderID rein. Dieser könnte nun in seiner Logik in der selbigen Methode verarbeitet werden.
$order = Order::find($order_id); // gebe
$sum_net = $sum_gross = $vat = 0; // Initialisierung der vars
foreach($order->order_items as $orderItem) // loop durch die einzelnen OrderItems
{
$orderItem->product; // hole das zugehörige Produkt, welches zum Order Item in Relation steht, ab
$sum_net += $orderItem->order_item_price * $orderItem->order_item_quantity; // Summe Netto alle Produkte / Items
$vat += ((($orderItem->order_item_price * $orderItem->order_item_quantity) * $orderItem->vat) / 100); // Steuer insgesamt
}
$order->sums = ["net"=>$sum_net,"vat"=>$vat,"gross"=>($sum_net+$vat) ];
return $order;
Hmm. Kann man machen, aber ist doch irgendwie ein wenig zu viel Business Logik drin, oder? Ein Controller soll doch nur die Anfrage annehmen und eine Antwort geben. Die Logik sollte dann ein Service übergeben werden. Der Service beinhaltet die Business Logik und arbeitet nur diese Logik ab. Der Service arbeitet aber nicht mit den Modelen zusammen. Den die Datenquellen bzw Datenlogik sind beim Repository verankert. Des Repository kennt die Modele und spricht sie entsprechend an.
Also schreiben wir es nun mal um.
Order Controller
use \App\Service\OrderService;
public function __construct()
{
$this->orderService = new OrderService();
}
public function order(Request $requerst, int $id)
{
$order_id = (int) $id;
return $orderService→getOrder();
}
Order Service
use \App\Service\OrderRepository;
public function __construct()
{
$this-> orderRepository = new OrderRepository();
}
public function getOrder(int $order_id) {
# hier kommen die Business Logiken rein
#- Validierung der Order ID
#- check ob Nutzer die Anfrage überhaupt machen darf (AUTH)
#- …
#- hole jetzt aus der Repository die Order ab:
$order = $orderRepository→getOrderById($id);
$sum_net = $sum_gross = $vat = 0; // Initialisierung der vars
foreach($order->order_items as $orderItem) // loop durch die einzelnen OrderItems
{
$orderItem->product; // hole das zugehörige Produkt, welches zum Order Item in Relation steht, ab
$sum_net += $orderItem->order_item_price * $orderItem->order_item_quantity; // Summe Netto alle Produkte / Items
$vat += ((($orderItem->order_item_price * $orderItem->order_item_quantity) * $orderItem->vat) / 100); // Steuer insgesamt
}
$order->sums = ["net"=>$sum_net,"vat"=>$vat,"gross"=>($sum_net+$vat) ];
return $order;
}
Order Repository
use \App\Models\Order;
public function getOrderById(int $id)
{
return Order::find($id);
}
Das wäre jetzt ein einfaches Beispiel. Aber wenn man ein ganzes Projekt in dieser Gangart umsetzt, wird man die Vorteile deutlicher zu spüren bekommen. Klassen lassen sich besser lesen und der wichtigste Punkt zum Schluss. Man kann dieses Pattern hervorragen testen.
Heute mal eine einfache Sache, falls man sie Klever einsetzt, eine Menge Arbeit abnehmen kann. Die Rede ist vom guten alten Shell-Script.
Wer ständig die gleichen Befehle absetzen muss, der kann sich doch automatisieren. Ich zum Beispiel nutze Shell Script für das Deployment Prozess. Also den fertigen Code von der Entwicklungsumgebung in die Produktionsumgebung zu schieben.
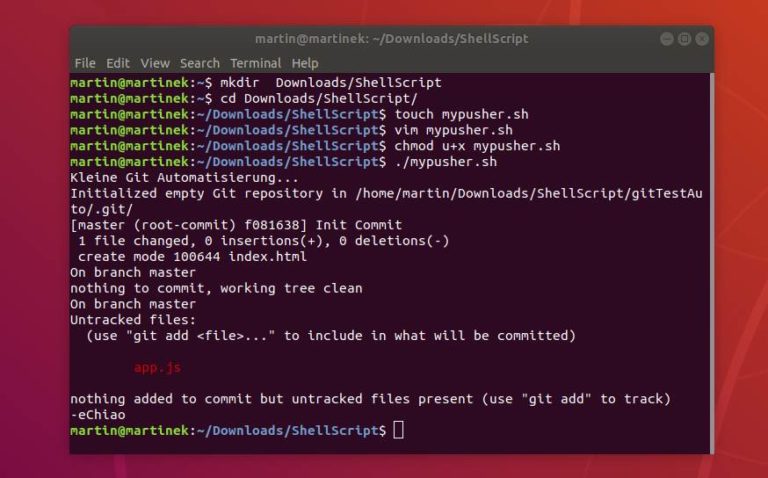
Fange wir an. Wir möchten ein Script erstellen, dass uns in einem Git Repository alle Änderungen verfolgt, commitet und in unser Remote Repository pusht.
Dafür brauchen wir erst einmal ein Shell Script bzw. Bash Script. Ein Bash Script hat die Dateiendung .sh.
In unserer Konsole geben wir also ein:
touch mypusher.sh
Dann öffnen wir unsere Datei und schreiben die Commands nieder die wir sonst in unserer Console hacken.
Jedes Shell Script fängt in der ersten Zeilemit dem sogenannten Shebang an. Diese Zeile sagt einfach nur mit welchem Kommandointerpreter bzw. welcher Shell das Script gelesen und ausgewertet werden soll. Statt #!/bin/bash kann man hier nun auch #!/bin/sh schreiben. Das führt dann dazu, dass das Script auch von BSD Systemen (Apple OS) gelesen werden kann.
Eine Besonderheit ist die Route. Grundsätzlich wird mit der Route in Shellscripten kommentiert. Eine Ausnahme gibt es nur in der ersten Zeile. In anderen Zeilen wäre das ein Kommentar:
# Hier kommt Kurt
So wird sind auch fast fertig. Nun speichern wir unsere Datei und gehen über zum letzten Schritt.
Mache die Datei „executable“
Ein Shell script muss ausführbar / executable sein. Dafür benötigt es besondere Rechte. Wir geben also nun in unserer Kommandzeile noch folgendes ein:
chmod u+x mypusher.sh
Und nun testen wir es mal. Allerdings nicht mit den Anweisungen von oben. Den dafür bräuchtet ihr ja noch ein entferntes Repository bei Github oder Bitbucket. Also ändern wir es mal kurz um:
Um das Script nun zu starten, geben wir über die Kommandozeile ein:
./mypusher.sh
A viola! Ich hoffe im groben merkt ihr, wozu so ein Shellscript alles helfen kann. Das hier ist die einfachste Variante. Wir können in Shellscripten mit Variablen, Parametern arbeiten. Wie einleitend bereits erwähnt. Es kann uns eine Menge arbeit abnehmen und wir können mehr Zeit in DevOp Themen investieren um beim nächsten Gespräch mit einem DevOp nicht ganz wie ein Trottel dazustehen.
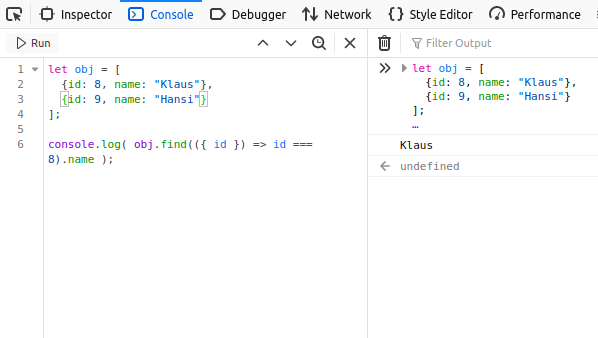
Vielleicht habt ihr das schon mal gesehen. Eine geschweifte Klammer in der Funktionsparameterliste. Was ist das und wozu ist das gut? Um hier Licht ins dunkel zu bringen, bediene ich mich eines kleine Fallbeispiels. Im folgendem Beispiel möchte ich aus einem Objekt den Namen der Person mit der id = 8 finden.
let obj = [
{id: 8, name: ‘Klaus‘},
{id: 9, name: ‘Hansi‘}
];
console.log( obj.find(({ id }) => id === 8).name );
// output: Klaus
Vielleicht erkennt der Ein oder Andere schon, was die geschweifte Klammer hier zu bedeuten hat. Ich helfe mal ein wenig! Die geschweifte Klammer bestimmt, welche Werte des Datenobjekts (obj) überprüft werden sollen und geben diese statt des ganzen Objektes nur die gewünschten Werte mit in die Funktion (ich nutze hier eine anonyme Funktion in der Pfeilfunktion-Schreibweise) . Da wir in unserem Beispiel die Überprüfung über die id durchführen, geben wir doch der Funktion gleich das mit was er benötigt. Die etwas längere Schreibweise wäre ansonsten diese:
Da wir nun die kurze (das Ding mit der geschweiften Klammer / Brakets) und die längere Version gegenüber gestellt haben, sollte nun den meisten klar werden, was die geschweifte Klammer bewirkt.
Ich hoffe ich konnte Euch einwenig helfen. Wo ich das erste Mal das gesehen habe sah ich ungefähr so aus wie der nette Koale im unteren Bild.
Heute mal leichte Kost. Laravel Model. Was ist das und was stellt man damit an, wie erstellt man ein Model und was kann es so alles.
Genug der langen Worte, fangen wir an!
Was ist ein Model?
Dafür blicken wir auf ein DesignPattern der Programmierung und zwar dem MVC Muster. MVC steht für Model, View und Controller.
Im groben kann man sagen, das Model handelt die Business Logik eines MVC basiertem Framwork. In Laravel enthält das Model die logische Struktur (Schema) und die Beziehungen (Relations) der dahinterliegenden Datenressourcen. Bei Laravel hat jede Datenbank Tabelle ein Model mit dem es mit der Anwendung kommuniziert. Also lesen, schreiben, updaten, löschen wird über das Model erst ermöglicht und verwaltet. Du findest seit Laravel 8 die Models unter app/models. Lange Zeit waren die Models im Root von app hinterlegt. Was keiner so richtig verstand, außer Oti (Taylor Otwell).
Wie kann man ein Laravel Model erstellen
Mit dem Kommandozeilen Tool artisan lässt sich bei Laravel so fast alles wichtige erstellen. Leider bis heute noch nicht die Views. Aber mit einem kleinen Workaround geht auch das. Aber zurück zum Thema. Ein Model erstellt ihr mit folgender Bash Zeile:
php artisan create:model <model-name>
Ersetzt <model-name> mit dem Namen den ihr wollt und zwar im Singular. Kleines Beispiel:
php artisan make:model Product -m
Wichtig ist hier anzumekren: dass ihr den Model namen in CamelCase schreibt und Singular bezeichnet sowie der erste Buchstabe groß sein sollte.
Man kann dem Artisan Command noch Parameter mitgeben. Zum Beispiel:
-m bzw. –migration (erstellt eine Migartiondatei)
-c (erstellt den dazugehörigen Controller. In umserem Fall also ProductController)
-r (erstellt eine Ressource. ProductRessource)
Wenn man den make:model Command ausführt erstellt uns Laravel artisan unter app/model/. Unser Model.
namespace App;
use Illuminate\Database\Eloquent\Model;
class Product extends Model
{
//
}
Ihr könnt Euch mal aus Jucks in eurem vendor Verzeichnis die abgleitete abstrakte Model (Illuminate\Database\Eloquent\Model) Klasse anschauen. Hier wird einem bewusst, welche Vielfältigkeit mn hier einstellen bzw. überschreiben kann. Ihr könnt in eurem Model die Default Werte einfach überschreiben. Kleines Beispiel: Die Membervariable protected $perPage = 15. Wollt ihr eine Pagination mit nur 10 Treffern pro Seite. Schreibt dazu dann protected $perPage = 10; und schon habt ihr den Defaultwert überschrieben.
Wichtige Variablen die ihr eventuell mal anfassen müsst wären:
protected $primaryKey = “id“; // Laravel nimmt an, dass jede Tabelle id als Primären Schlüssel verwendet. Falls das nicht so ist könnt ihr dies hier ändern
public $timestamps = false; // Laravel fügt von Haus aus jeder Tabelle noch zwei Spalten (created_at und updated_at) hinzu. Falls ihr das nicht wünscht, überschreibt die public Membervariable $timestamp mit false;
protected $hidden = [ ‘password’, ‘remember_token’]; // wenn Ihr ein Model abfragt werden euch alle Spalten ausgeliefert. Es sein den ihr wollt, dass bestimmte Felder nicht angezeigt werden sollen. Wie zum Beispiel das Passwort bei einer Abfrage nach dem User::find(1);
protected $fillable = [‘name’,’email’,’password’]; // sind Felder die geupdated werden dürfen.
protected $guarded = []; // Ist ein Array mit Spaltennamen des Models die nicht geupdated werden dürfen
Ein sehr großes Topic vor beginn einer neuen Applikation ist die Authentifizierung. Bei der Hypoport AG in Berlin wurde bei einem Projekt ein ganzer Monat mit mehreren Entwicklerteams das Thema Login geplant. In anderen Projekten, die sicher laufen sollen, verhält sich das ähnlich.
Deswegen sollte das Thema von Anfang an immer gut durchdacht sein. Erspart einem eine Menge Zeit und Ärger.
Laravel bietet eine Reihe von Authentifizierung Bibliotheken an. Die Umfänglichste ist Laravel Passport. Eine smart, elegante ist JWT. Genau diese möchte ich heute euch kurz mal vorstellen.
JWT steht für JSON Web Token
Bei der Komminkation zwischen dem Browser und dem Server ist es notwendig den Nutzer eindeutig zu identifizieren. Es geht Sessionbasiert oder wie beim JWT token basiert. Der Ablauf sieht wie folgt aus:
Nutzer besucht unserer Website
Nutzer logt sich mit seiner Emailadresse und Passwort über das entsprechende Login Formular ein
Server überprüft seine Anfragen und bei erfolgreichem Abgleichen gibt der Server dem Browser einen Token zurück.
der zurückgelieferte Token wird entweder im LocalStorage oder in einem Cookie gespeichert
beim nächsten Request zu Server wird der Token im Header als Bearer mitgeliefert (hier wird gerne der Header Accept vergessen. Der da sein sollte application/json)
der Server kann anhand des Token den Nutzer identifizieren und weiß zumindest wem er nun die Antwort schickt
In unserem Beispiel möchten wir mal eine ganz einfache Nutzer Verwaltung erstellen. Der Einfachheitshalber regeln wir das alles ohne Controller sondern direkt im Router (api.php).
1. Wir installieren Laravel
2. Wir installieren JWT Auth mit
composer require tymon/jwt-auth
Wenn Du jwt-auth nicht installieren kannst, weil diese oder eine ähnliche Ausgabe in deiner Console erscheint:
Your requirements could not be resolved to an installable set of packages.
Problem 1
- Root composer.json requires tymon/jwt-auth ^0.5.12 -> satisfiable by tymon/jwt-auth[0.5.12].
- tymon/jwt-auth 0.5.12 requires illuminate/support ~5.0 -> found illuminate/support[v5.0.0, ..., 5.8.x-dev] but it conflicts with another require.
Installation failed, reverting ./composer.json and ./composer.lock to their original content.
Kannst Du es mal mit diesem composer Befehl versuchen. Denn wahrscheinlich gibt es bei Dir ein kleines Versionsproblem.
5. Wir implementieren in unserem User Model die Klasse Tymon\JWTAuth\Contracts\JWTSubject
– use Tymon\JWTAuth\Contracts\JWTSubject
– wir implementieren das Model User mit dem JWTSubject Interface
class User extends Authenticatable implements JWTSubject
– wir fügen die zwei JWTSubject Methoden hinzu:
getJWTIdentifier(): Gibt den JWT Token zurück.
getJWTCustomClaims(): Gibt ein Array, mit benutzerdefinierten Benutzeranforderungen zurück
**
* Get the identifier that will stored
*
* @return mixed
*/
public function getJWTIdentifier() {
return $this->getKey();
}
/**
* Return a key value array with containing any custom claims
*
* @return array
*/
public function getJWTCustomClaims() {
return [];
}
6. Wir konfigurieren unser Auth Guard und sagen dem System , dass wir die api Anfragen mit JWT authentifizieren möchten
Der Ein oder Andere wird im Laufe seiner Javascript Entwicklung an einen Punkt gekommen sein zwei JavaScript Objekte zusammenzuführen. Quasi „mergen“. Ein Fallbeispiel könnte sein, ihr habt eine JS Klasse mit einer Membervariablen vom Typ „Object“ die Texte im key-value beinhaltet.
Nun wollt ihr statt „Tschüßi Kowski“ doch lieber Auf Wiedersehen ausgeben. Eine Möglichkeit ihr ändert es in der Klasse. Die andere ihr nutzt einen Setter. Also implemntiert ihr in eure Klasse folgendes:
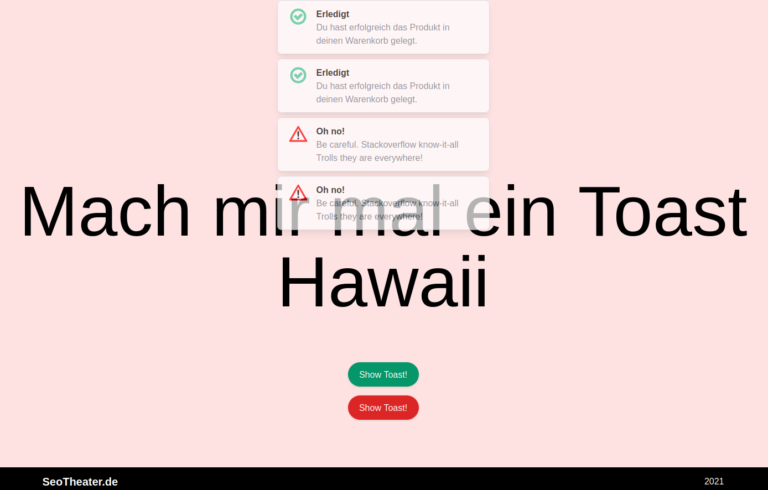
Stellt euch vor ihr wollt für ein Shop eine Notification oder auch bekannt als Toast ausgeben. Zum Beispiel Produkt in Warenkorb gelegt. Oder „ups, leider ist das Produkt in ihrer Größe nicht mehr vorhaben. Es gibt hier echt viele und gute Bibliotheken. Aber ich will selber eine Toaster Klasse bauen, weil mir der Overhead gerade nicht passt. Ansonsten immer gerne. Weil man muss ja nicht das Rad jedes Mal von vorne erfinden.
Die Vorüberlegung
– die ToastHawaii Klasse kann bei der Initiierung ein Config Objekt mitgegeben werden. In meinem Beispiel ist nur die Verweildauer des Toast in der Config enthalten. Man kann es hier noch genügend anreichern. Position des Posts, Style Klassen und und und.
– mit der Toast Methode makeToast( {title: <string>, msg: <string>,style:<string>}) kann ein Toast angetriggert werden – Wenn mehrere Toast hintereinander abgefeuert werden hänge den neusten Toast unten ran – Im Quelltext befindet sich nur Componenten Container der mit der id toast-hawaii angesprochen wird
Der Aufbau der Klasse
– constructor(paras = {}), – getIcon() – makeToast() – die Klasse beinhaltet das HTML und kann somit für andere Toastdesign problemlos angepasst werden – makeToast kann default Config Parameter die bei der Instanziierung des Objekts mitgegeben wurden überschreiben (zum Beispiel Anzeigedauer / duration) – makeToast besitzt Pflichtfelder die als Parameter vom Type Objekt mitgegeben werden ( {title:‘‘, msg: ‘‘, style=‘‘} )
Die Umsetzung
– HTML – VanillaJS – TailwindCSS
Es würde mich riesig freuen, wenn ihr auf GitHub das Projekt Folkt und mit weiterentwickelt. Um somit ein solides und einfaches sowie flexibles Notifikation System in Tailwind und purem Javascript anzubieten.